Kiểm định chi bình phương trong stata
Phần này nhóm Thạc Sĩ sẽ cung cấp một cái nhìn tổng quan ngắn gọn về một số ví dụ kiểm định thống kê phổ biến cơ bản trong Stata.Các lệnh được sử dụng là:
ttesttabulate , chi2 exactcorrelatepwcorrdrop ifregressonewayHãy sử dụng file dữ liệu auto cho các ví dụ .
Bạn đang xem: Kiểm định chi bình phương trong stata
sysuse auto
Lệnh ttest
Sử dụng t-test để so sánh số dặm miles trên một xăng gallon (mpg) giữa xe hơi nội địa và xe hơi nhập khẩu.Ở đây nói thêm đây là đơn vị đo lường ở Mĩ, một gallon =3.7854 lít , còn một dặm miles bằng 1.6 kilometttest mpg , by(foreign)Two-sample t test with equal variances
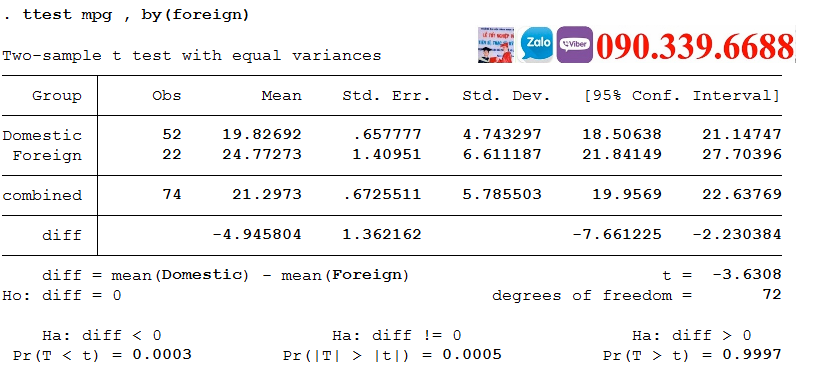
Như bạn thấy trong kết quả ở trên, xe trong nước có mpg thấp hơn đáng kể (19,8) so với xe nước ngoài (24,7). Nghĩa là xe trong nước chạy hau xăng hơn xe nước ngoài nhập khẩu.
Kiểm định chi bình phương Chi-square stata
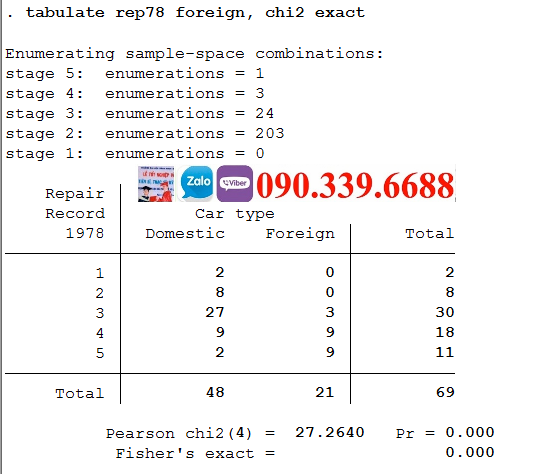
Hãy so sánh xếp hạng sửa chữa (rep78) của ô tô nước ngoài và ô tô trong nước. Chúng ta có thể làm một bảng chéo crosstab của rep78 và foreign. Chúng ta có thể muốn hỏi liệu các biến này có độc lập hay không. Chúng ta có thể sử dụng tùy chọn chi2 để yêu cầu một kiểm định chi-bình phương về tính độc lập giữa hai biến đồng thời thể hiện bảng chéo crosstabtabulate rep78 foreign, chi2

Pearson chi2(4) = 27.2640 Pr = 0.000Giá trị Pr =0.000 chứng tỏ có mối quan hệ giữa rep78 và foreign. Nghĩa là 2 biến này không độc lập.Chi-square không thực sự hợp lệ khi bạn có các ô trống. Trong những trường hợp như vậy khi bạn có các ô trống hoặc các ô có tần số nhỏ, bạn có thể yêu cầu kiểm định “Fisher’s exact test” với tùy chọn exact.tabulate rep78 foreign, chi2 exact
Tương quan correlation
Chúng ta có thể sử dụng lệnh tương quan correlation để lấy tương quan giữa các biến. Hãy xem xét mối tương quan giữa price mpg weight và rep78. (Sử dụng rep78 trong mối tương quan mặc dù nó không liên tục, nghĩa là số liệu bị thiếu missing value, để minh họa điều gì sẽ xảy ra khi ta sử dụng mối tương quan với các biến có dữ liệu bị thiếu.)correlate price mpg weight rep78
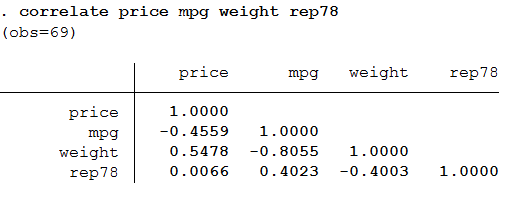
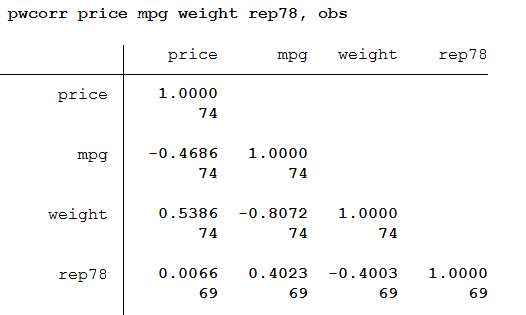
Lưu ý rằng kết quả ở trên đã nói (số quan sát obs = 69). Lệnh tương quan xóa drop dữ liệu theo nguyên tắt listwise, có nghĩa là nếu bất kỳ biến nào bị thiếu dữ liệu ở dòng quan sát đó, thì toàn bộ quan sát ở dòng đó sẽ bị bỏ qua khỏi phân tích tương quan.Chúng ta có thể sử dụng pwcorr (tương quan theo từng cặp pairwise correlations) nếu chúng ta muốn có được các tương quan xóa dữ liệu bị thiếu trên cơ sở từng cặp pairwise thay vì cơ sở theo danh sách listwise. Nói đơn giản, vì tương quan là xét mối quan hệ giữa hai biến, nếu hai biến đó có đầy đủ số liệu không bị thiếu thì đưa tấ cả các quan sát vào để chạy tương quan, bất chấp 1 biến khác bị thiếu. Chúng ta sẽ sử dụng tùy chọn obs để hiển thị số lượng quan sát được sử dụng để tính toán mỗi mối tương quan.pwcorr price mpg weight rep78, obs
Xem thêm: Chế Độ Eco Máy Lạnh Casper Tiết Kiệm Điện 40%, Chỉ Tốn 4K Một Đêm
Hồi Quy
Hãy xem xét thực hiện phân tích hồi quy trong Stata. Đối với ví dụ này, hãy loại bỏ các trường hợp mà rep78 là 1 hoặc 2 hoặc bị thiếu.
drop if (rep78 (15 observations deleted)Bây giờ, hãy dự đoán mpg từ giá cả price và trọng lượng weight. Như bạn thấy bên dưới, trọng lượng là một yếu tố dự đoán đáng kể về mpg, nhưng giá thì không( căn cứ vào p value của price và weight, cái nào regress mpg price weight
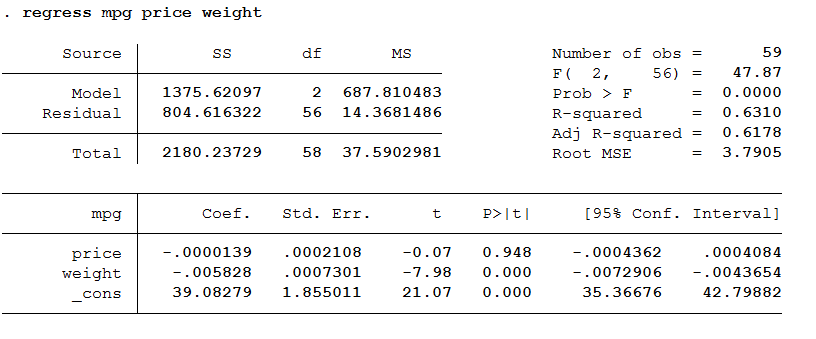
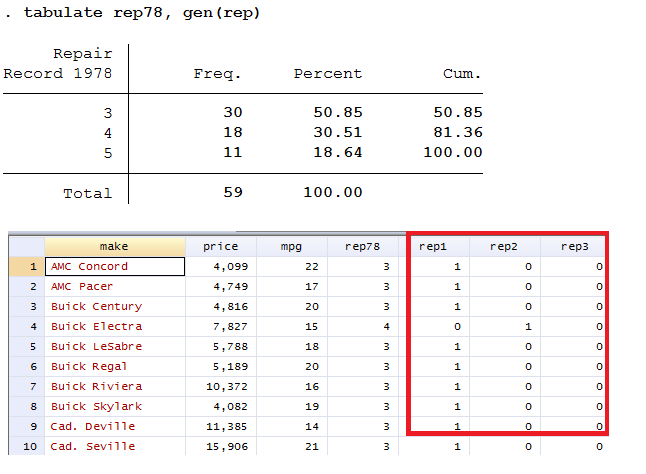
Điều gì sẽ xảy ra nếu ta cũng muốn dự đoán mpg từ rep78. rep78 thực sự là một biến phân loại hơn là một biến liên tục. Để đưa nó vào hồi quy, chúng ta nên chuyển đổi rep78 thành các biến giả. May mắn thay, Stata làm cho các biến giả dễ dàng bằng cách sử dụng tabulate. Tùy chọn gen (đại diện) cho Stata biết rằng chúng ta muốn tạo các biến giả từ rep78 và chúng ta muốn gốc của các biến giả là đại diện.tabulate rep78, gen(rep)
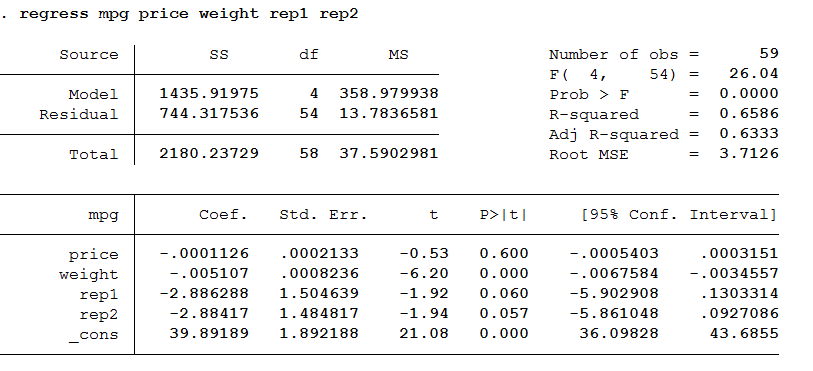
Phân tích phương sai Analysis of variance
Nếu bạn muốn thực hiện phân tích phương sai để xem xét sự khác biệt trong mpg giữa ba nhóm sửa chữa, bạn có thể sử dụng lệnh oneway để thực hiện việc này.oneway mpg rep78Analysis of Variance
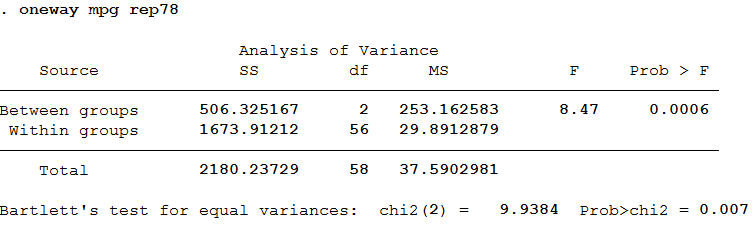
Nếu bạn bao gồm tùy chọn tabulation, bạn sẽ nhận được trung bình mpg cho ba nhóm rep78, điều này cho thấy nhóm có xếp hạng sửa chữa tốt nhất (rep78= 5) cũng có mpg cao nhất (27,3).oneway mpg rep78, tabulate











